1.0
![[Note]](resources/images/admons/note.png) | Note |
|---|---|
|
This documentation is currently being written. Therefore, large parts of the documentation are still missing and will be added step by step. |
This developer documentation describes the concepts behind the jLexis Vocabulary Trainer's source code and details the different aspects of the software design. The document's intended audience are developers who want to contribute to the core system of jLexis. Plugin developers who want to write language plugins for jLexis are encouraged to consult the extra document especially available for this topic.
This chapter details the data model for jLexis. Understanding this data model is crucial if you wish to develop language plug-ins or intend to contribute to the core code. The flexibility of jLexis is largely based on its design of the data model and how this data is processed.
One of the main ideas behind jLexis is to provide a base application which is completely language-independent. As such, it serves as a foundation for add-ons which can build on the provided general functionality. Plug-ins only have to provide those distinctive features which are needed for studying some particular foreign language. This allows for keeping all language-specific data and data processing facilities separate from the main application. With this, the applicability of jLexis is not limited to only a handful of standard foreign languages.
In order to achieve that separation of concerns, the base application has to provide generic data storing and data processing facilities which are general enough to be suitable for every conceivable natural or artificial language.
The following sections comprehensively explain how the data model of jLexis is designed and how this design enables language plug-ins to store their language-specific data in a language-independent environment provided by the jLexis main application.
At the heart of the data model for a vocabulary trainer lies the vocabulary data itself. This comprises all the data a learner needs for studying a foreign language. This can be, for example, verbs, nouns, and adjectives, example sentences, commentary data or phonetic transcriptions. It is easy to see that while being the most important data for learning languages, it is also the most language-specific. For example, some languages have more genders and different gender inflections than others. Or, similarly, the declension of verbs is formed differently in every language which also varies with the availability of grammatical cases. Considering these facts, every foreign language has its own demands for handling vocabulary data. For languages with a more complex grammar, it is necessary to memorize more vocabulary data, while languages with a simpler grammar do not demand especially sophisticated vocabulary data.
The core class for working with vocabulary data is
info.rolandkrueger.jlexis.data.vocable.Vocable. This class represents one atomic unit of
vocabulary data. More specifically, a Vocable contains all
data which is relevant for learning one particular word or phrase in some
foreign language. This comprises the term in the learner's native language
and its translation for a foreign language. This data may also be
accompanied by exemplifications or commentaries or any arbitrary data
which may be relevant to this term. Due to the fact that jLexis does not
restrict the number of foreign languages you can learn with it
simultaneously, a Vocable may contain translations for more
than one foreign languages.
Example 2.1. Example for a vocable
The following example is a typical multi-language vocable which
could be used by a learner whose native language is German and who is
learning English and Swedish as foreign languages. All the data shown
below is stored in a single Vocable object. The same data
could originate e.g. from a set of flash cards with vocabulary
data.
| German | English | Swedish |
|---|---|---|
verdienen Example: seinen Lebensunterhalt verdienen, er verdient 6000 Kronen im Monat | (to) earn [ɜːn] Example: he ~ed a lot of money Comment: (of a person) obtain (income) in the form of money in return for labor or services | förtjäna, ~r, ~ade [fœ(r)'çɛːna] Example: förtjäna sitt levebröd, han förtjänar sex tusen kronor i månadenComment: förvärva som lön eller vinst |
Lets have a look at how a Vocable object is composed.
For a schematic depiction of a Vocable object see Figure 2.1. Such an object
basically consists of a single hash map containing a mapping of
info.rolandkrueger.jlexis.data.languages.Language objects on corresponding instances of class
info.rolandkrueger.jlexis.data.vocable.VocableData. A Language represents either the
user's native language or the foreign languages she's learning. The
VocableData objects hold the respective vocabulary data for
each language. Hence, the languages appearing in a vocable are linked with
data objects holding the corresponding data.
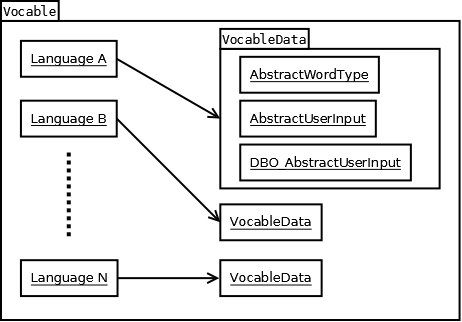
Now let's take a closer look at the VocableData class.
Objects of this type hold all relevant data for one specific language and
one particular vocabulary term. In the example above, this may be the data
for the English verb to earn. Every
VocableData object is constituted of three objects holding the
vocabulary data itself together with a specification of the data. These
objects are of the following types:
-
info.rolandkrueger.jlexis.data.vocable.AbstractWordType -
info.rolandkrueger.jlexis.data.vocable.AbstractUserInput -
info.rolandkrueger.jlexis.data.vocable.DBO_AbstractUserInput
We will discuss these classes in more depth shortly. Let's first try
to get a general understanding for the intent of these classes. An
AbstractWordType gives a specification of the
VocableData. That is, it defines to which grammatical type
this data belongs. Subclasses of AbstractWordType may
represent verbs, nouns, adjectives, or phrasal verbs of a particular
language.
Since every word class (in a grammatical sense) has its own demands
for storing and handling lexical data, subclasses of
AbstractWordType can implement this specific behavior. All
organizational work regarding a lexical word class is done with
AbstractWordTypes. An object of this class serves as a factory
for AbstractUserInput objects (see below), keeps an identifier
for the lexical class it represents, and provides appropriate user input
panels for its vocabulary data.
While an AbstractWordType specifies the specific part of
speech to which some Vocable object belongs, subclasses of
AbstractUserInput are responsible for handling the data
itself. Due to the fact that each particular word class has its own
requirements for what data has to be stored and how, subclasses need to be
derived from AbstractUserInput which parallel the class
structure of AbstractWordType's subclasses. For example, if
there is a class SwedishNounWordType specifying the
lexical category of Swedish nouns, a corresponding class
SwedishNounUserInput should exist accommodating the
different inflections of some Swedish noun.
The last remaining element contained in a VocableData
object is class DBO_AbstractUserInput. This is merely a data
container holding the concrete vocabulary data for an
AbstractUserInput. It is used as a data transfer object for
storing the data in a database and retrieving it from there. The
abbreviation DBO stands for Database Object. This class
does not offer any particular business functionality.
Let us now study these three classes in more detail.
Language plugins are the core concept behind the flexibility of jLexis to enable studying a particular foreign language with jLexis as a language-independent program. These plugins add all the specifics which make each language unique to the vocabulary trainer. While the jLexis main program can manage vocabulary data at the most general level, a language plugin gives jLexis all hints and functions necessary for working with one particular foreign language.